Welcome! I’m Rajesh More—a Technical Architect with 10+ years of expertise in designing,deploying, and scaling AI/ML solutions across healthcare, e-commerce, fintech, and
manufacturing.Currently at CWX, I lead global AI teams, drive research, and architect production-grade AI pipelines on GCP, AWS, and Azure.

My journey blends deep technical skills with a passion for teaching and mentoring. Through
Deccan AI School, I guide ambitious learners toward impactful AI careers.
Whether you’re a recruiter, a collaborator, or an aspiring student—let’s connect and build
the future together

Built production ML pipeline for medical imaging using GCP, Kubeflow, and deep learning models. Automated training, deployment, and monitoring for scalability.

Designed an enterprise search solution using GCP tools (DLP API, Firestore, BigQuery, GCS, GAR, GKE). Led a 6-member AI, Data & Infra team to deliver a secure and scalable application.
Analyzed customer purchase journey (page views, cart actions, purchases) across mobile vs desktop. Measured CTR and conversion rates for optimization.

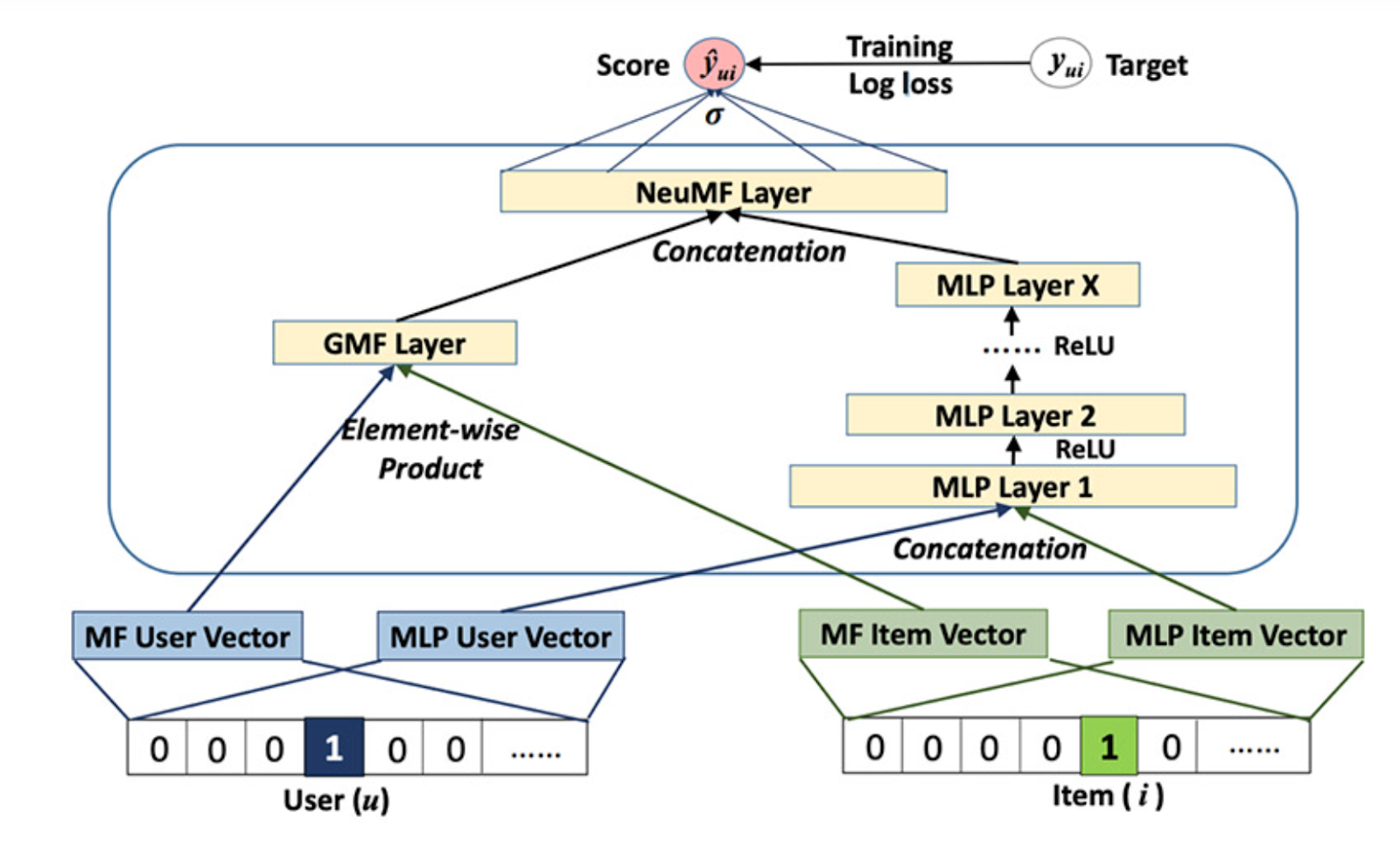
Orchestrated image classification models using Kubeflow & Vertex AI pipelines. Managed continuous training, versioning, and deployments with BigQuery, GCS, Jenkins & GitHub.

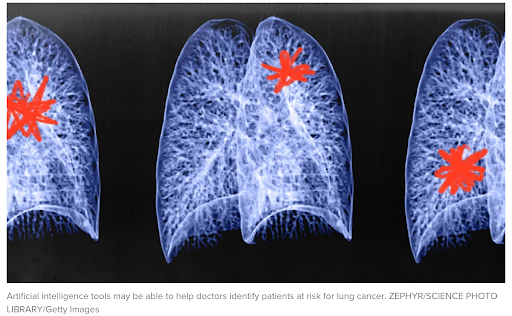



predictions.
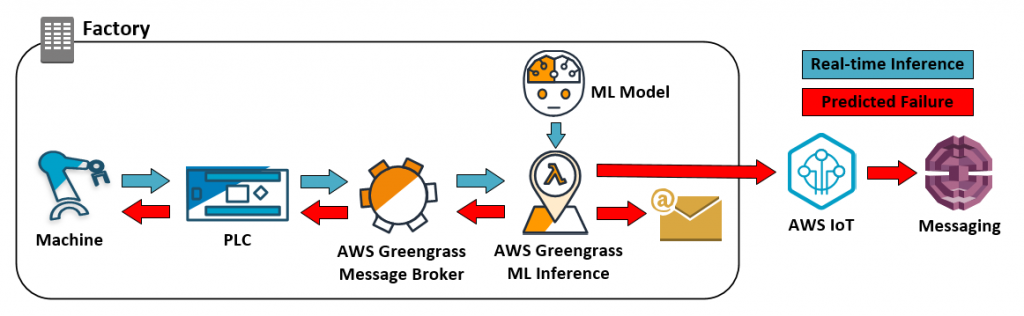


Recent technological advancements have enabled individuals to interact in various manners using multimedia. The growing use of wearable gadgets, medical detectors, and improved medical facilities has resulted in the continuous production of massive amounts of multimedia data. The application of multimedia techniques in healthcare systems also enables the storage, processing, and transmission of patient information provided in several formats like images, text, and voice via the internet through different smart devices.

A cloud computation platform that acquires complicated user demands with multiple subtasks is evaluated in terms of response time. To shorten servicing duration, operations are broken down into lesser parts and handled simultaneously. Measuring response times in a multilayer network is an important but difficult analytical component in Quality of Service (QoS) evaluation. Modulating the functioning of QoS variables, including response time and throughput, can lead to more effective cloud-based services for customers.
Modern analytical approaches can provide accurate estimations of average response times. Nevertheless, precisely estimating response time dispersion for service-level evaluation is a difficult issue. Precise estimation of absent QoS data is crucial for proposing acceptable online services to end users, as the QoS variable matrices are typically lacking. This investigation developed an artificial neural network (ANN) framework to forecast absent QoS data for estimating response time. This study compares the performance of various ANN methods for predicting QoS response time. The Bayesian-Regularized ANN method outperforms other learning methods in terms of performance.

Recent advancements in computing systems and Big Data platforms have facilitated the development of artificial intelligence (AI). AI algorithms have proven to be quite useful in big data processing, particularly data classification. Unstructured data is commonly collected through social networking sites such as Facebook, Instagram, Twitter, and others. Converting unstructured data to structured data is a time-consuming activity. Unstructured data is transformed into structured data using various AI algorithms.
The unstructured data for this study was initially gathered by using the Instagram application program interface (API) feed from a popular social networking site. Furthermore, utilizing the gathered database different AI algorithms such as neural network (NN), k-nearest network (KNN), super vector machine (SVM), random forest (RF), decision tree (DT), and logistic regression (LR) is applied in this study. The results imply that SVM algorithm performance is higher compared to the other five AI algorithms.
We’re here to assist you—reach out during our working hours or contact us anytime online.
© 2023 Created with Digital Partners
